
Obsah
1. Můžeme věřit překladačům? Projekty řešící schéma „důvěřivé důvěry“
2. Klasický problém slepice-vejce
3. Kam schovat zadní vrátka ve chvíli, kdy je zdrojový kód překladače k dispozici?
4. Ukázka z povídky „Coding Machines“
5. „Cykly“ v použitých nástrojích
6. Možná řešení „cyklu“ v použitých nástrojích
7. Nástroje psané v assembleru
8. Zajímavá lekce z minulosti: assemblery A1 a A2
10. Základní sada nástrojů vyvinutých v rámci projektu Stage0
11. Další nástroje, které nalezneme v projektu Stage0
14. Použití druhého překladače pro zjištění modifikovaného kódu
16. Postačuje provést překlad gcc s využitím tcc?
17. Alternativní cesta: jednoduché a verifikovatelné virtuální stroje
1. Můžeme věřit překladačům? Projekty řešící schéma „důvěřivé důvěry“
„Recipe for yogurt: Add yogurt to milk.“ – Anon.
Překladač programovacího jazyka je jeden ze základních nástrojů, s nímž se vývojář dennodenně setkává. Moderní překladače jsou velmi složité nástroje, na jejichž korektní funkci do značné míry závisí i korektnost výsledné aplikace nebo knihovny, kterou překladačem získáme. Nabízí se tady zajímavá otázka – dá se do překladače ukrýt takový kód, který by pozměnil chování výsledné (překládané) aplikace, například do ní vložit zadní vrátka, upravenou funkci pro kontrolu hesel, špatný generátor náhodných čísel atd.? Ukazuje se, že to možné je, a to dokonce i ve chvíli, kdy máme k dispozici zdrojové kódy takového překladače a tedy teoretickou kontrolu nad tím, co se v počítači děje. Na druhou stranu ovšem existuje i obrana proti útokům vedeným přes překladač. S oběma koncepty – útokem i obranou – se dnes budeme zabývat (i když prozatím ne do takové hloubky, jaké by si toto téma zasloužilo).

Obrázek 1: Idylická situace – překladač přesně přeloží náš zdrojový kód a výsledná binární podoba aplikace dělá přesně to, co bylo ve zdrojovém kódu napsáno.
2. Klasický problém slepice-vejce
Jádro celého problému důvěryhodnosti nebo nedůvěryhodnosti překladače spočívá v tom, že existuje způsob jak zajistit, aby se „čisté“ zdrojové kódy, které při kontrole programátorem evidentně žádná zadní vrátka neobsahují, přeložily do spustitelného binárního kódu, popř. do staticky nebo dynamicky linkované knihovny, kde už ovšem zadní vrátka být mohou. Běžní programátoři totiž (mj. i z časových důvodů) podrobně nezkoumají výsledek překladu, tj. relativně špatně rozluštitelný strojový kód, navíc kombinovaný s daty atd. Navíc – pokud už nevěříme použitému překladači, jak můžeme vědět, že ve výsledném binárním souboru budou správné ladicí informace? Překladač totiž může poměrně snadno do strojového kódu přidat instrukce, které nebudou mapovány na žádný zdrojový řádek. Koncept podobného útoku byl rozpracován již v roce 1974 ve zprávě Multics Security Evaluation: Vulnerability Analysis.

Obrázek 2: Pokud je překladač z nějakého důvodu upraven, může produkovat binární kód, který (možná) odpovídá zdrojovému kódu, ale taktéž může obsahovat nějaká zadní vrátka (nebo obecně trojského koně).
3. Kam schovat zadní vrátka ve chvíli, kdy je zdrojový kód překladače k dispozici?
Mohlo by se zdát, že pokud jsme v situaci, kdy máme k dispozici zdrojový kód překladače (například překladače céčka z projektu GCC), máme vyhráno, protože můžeme libovolně dlouho a s vynaložením libovolně vysokých finančních prostředků analyzovat zdrojové kódy překladače a ověřit si tak, že žádná zadní vrátka neobsahuje. Navíc můžeme tento zdrojový kód přeložit a získat tak druhou binární kopii GCC, která bude bezpečná a verifikovaná (však také vznikla překladem z verifikovaných zdrojových kódů ne?):

Obrázek 3: Ve chvíli, kdy není překladač nijak napaden, vznikne překladem jeho vlastních zdrojových kódů opět „čistý“ (nenapadený) překladač. Pokud se jedná stále o stejnou verzi, měly by být binární obrazy totožné (předpokládáme použití stejných přepínačů, shodnou architekturu, žádná časová razítka atd.).
Ve skutečnosti však může být situace mnohem horší, protože napadený překladač může být upraven tak sofistikovaně, že pozná, že překládá sám sebe a vloží do výsledného binárního kódu příslušnou část pro generování trojského koně ve chvíli, kdy bude nový překladač použit:
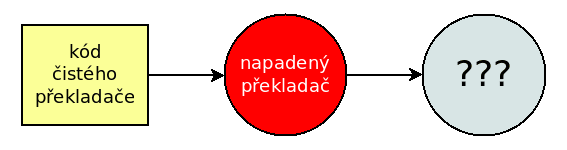
Obrázek 4: Ve chvíli, kdy nemůžeme důvěřovat binárnímu kódu překladače, není vůbec jisté, co vznikne překladem čistých zdrojových kódů. V nejhorším případě musíme předpokládat, že získáme opět napadený překladač!
Že je takový útok prakticky možný, ukázal už Ken Thompson a po něm mnozí další. Ve známých případech se většinou jednalo o akademické práce, které měly Thompsonovu teorii dokázat s využitím různých programovacích jazyků (typicky se jednalo o C, Scheme, z poslední doby je například článek Reflections on Rusting Trust popř. Reflections on Trusting Trust for Go) apod. Zajímavá (ovšem zdrojovými kódy nedoložená) je také historka prezentovaná v článečku What is a coder's worst nightmare?. Skutečnými útoky tohoto typu se pravděpodobně nikdo nechlubí (ani útočník, ani oběť), ale víme například o viru The W32/Induc-A virus určený pro programy psané v Delphi, popř. o Xcodeghost (napadený překladač Xcode).
Podívejme se nyní na známou ukázku Kena Thompsona. Ukázka platí pro programovací jazyk C, ale lze ji samozřejmě aplikovat na prakticky jakýkoli jiný překladač.
První fáze spočívá v úpravě zdrojových kódů překladače a vložení dvou nových funkcí:
- Pokud překladač pozná, že se překládá běžná aplikace, vloží do ní zadní vrátka (například si otevře nějaký port, na kterém bude aplikace poslouchat).
- Pokud překladač pozná, že překládá sám sebe, zajistí, aby se v nové binární podobě překladače objevil kód z bodu číslo 1.

Obrázek 5: První fáze popsaná v předchozím textu.
Nyní jsme tedy v situaci, kdy se napadený překladač dokáže sám šířit nezávisle na tom, že vstupní zdrojové kódy jsou verifikovány:

Obrázek 6: Situace, ve které máme překladač, který ze svého „čistého“ zdrojového kódu vygeneruje napadený binární podobu překladače.
Důležité je, aby útočníkem upravené zdrojové kódy nebyly nikde distribuovány. Postačuje pouze jednou (na začátku) rozšířit napadený překladač, který (při vhodném naprogramování) může zadní vrátka šířit libovolně dlouho:

Obrázek 7: Takto musí celou situaci vidět zbytek světa nebo alespoň oběť útoku.
if ((err = SSLHashSHA1.update(&hashCtx, &signedParams)) != 0)
goto fail;
goto fail;
4. Ukázka z povídky „Coding Machines“
Následuje ukázka z krátké povídky „Coding Machines“, kterou si můžete celou přečíst na stránce https://www.teamten.com/lawrence/writings/coding-machines/. Povídka je založena na podobném konceptu, jaký byl naznačen výše:
“It’s just so odd that the C source would be clean but the assembly have these weird op-codes,” I said.
“I thought you had tracked it down to the compiler,” said Dave.
“I don’t mean in your code, I mean in the compiler itself.”
“The compiler could be responsible for that too.”
“No, I checked the code.”
“But the code is compiled by the compiler.”
5. „Cykly“ v použitých nástrojích
Jeden z důvodů, proč může být podvržení překladače navržené Kenem Thompsonem úspěšné, spočívá v tom, že mnoho v současnosti používaných „toolchainů“ obsahuje cyklus, tj. nějaký nástroj (typicky právě překladač) je použit pro překlad sama sebe. Cyklus může být ovšem i nepřímý, protože například prakticky všechny nástroje GCC jsou psány v céčku a pro překlad céčka jsou zapotřebí právě tyto nástroje :-)

Obrázek 8: Některé (skutečně jen některé) nástroje použité pro překlad céčkovských zdrojových kódů.
Znalost cyklu v toolchainu je důležitá: útočník například bude vědět, že potenciální oběť používá dva různé překladače (řekněme GCC a LLVM), takže by mohla napadení jednoho z těchto překladačů odhalit, například způsobem naznačeným v dalších kapitolách. Ovšem překladač samozřejmě není jedinou součástí toolchainu, protože lze napadnout například assembler (pokud se volá), linker, nástroj ar apod. A ve chvíli, kdy jsou tyto nástroje použity oběma překladači, problém stále přetrvává, i když je nutné poznamenat, že úprava překladače je potenciálně nejjednodušší, protože tento nástroj má nejvíce informací o kódu, který má pozměnit.
6. Možná řešení „cyklu“ v použitých nástrojích
Existuje několik metod, jak vyřešit „cyklus“, o němž jsme se zmínili v předchozí kapitole. Buď je možné použít alternativní (druhý) překladač, který ani nemusí být výkonný, ale postačuje, aby byl verifikován (nebo prostě, abychom věřili, že neobsahuje žádná zadní vrátka). Touto možností, jejíž správnost byla dokázána i matematicky, se budeme zabývat ve čtrnácté kapitole. Ovšem z pohledu programátora je zajímavější odlišný přístup, který spočívá v tom, že se bude používat celá „pyramida“ nástrojů. Na nejnižší úrovni budou použity velmi primitivní nástroje, jejichž chování si ovšem může každý znalý uživatel ověřit. Na každé vyšší úrovni jsou přidávány složitější nástroje s větší úrovní abstrakce, až nakonec skončíme u překladače vyššího programovacího jazyka (například právě céčka). Ovšem ten vznikne sadou kroků, z nichž každý je verifikovatelný; tudíž i výsledný překladač by neměl obsahovat žádné trojské koně ani kód pro jejich generování.

Obrázek 9: Strohé uživatelské rozhraní monitoru pro československé mikropočítače PMD-85. Kdo říká, že minimalismus je „in“ až v současnosti?
7. Nástroje psané v assembleru
Jen malá poznámka k předchozí kapitole. Mohlo by se zdát, že pokud si dáme tu práci a vytvoříme sadu základních nástrojů přímo v assembleru, bude problém „důvěřivé důvěry“ spolehlivě vyřešen. Ovšem ve skutečnosti je většina v současnosti používaných assemblerů (minimálně těch určených pro PC a Linux) naprogramována právě v programovacím jazyku C nebo C++, takže problém ve skutečnosti přetrvává (bylo by ovšem zajímavé zjistit, zda už někdo provedl úpravu céčka tak, aby byl napaden jím překládaný assembler). Můžeme se ostatně podívat na zdrojové kódy dvou známých assemblerů – GNU Assembleru i NASMu (Netwide Assembleru):

Obrázek 10: Někteří programátoři dokázali i v primitivním monitoru naprogramovat rozsáhlé aplikace a to včetně her. V takovém případě se pro ruční převod assembleru do strojového kódu používaly takovéto tabulky (i když osobně znám člověka, který si dokázal zapamatovat kódy všech strojových instrukcí i jejich variant).
8. Zajímavá lekce z minulosti: assemblery A1 a A2
Bootstraping, který řeší problém cyklu ve vývojových nástrojích, se používal, resp. musel použít i v minulosti. Důvodem byl fakt, že pro první vyráběné mainframy bylo nutné nějakým způsobem vytvořit překladač či alespoň assembler (později bylo samozřejmě možné provést cross překlad na jiné platformě, ovšem někde se začít musí :-). Zcela první nástroj pro nový mainframe byl vytvořen a přeložen ručně na papíře; následně byl výsledek představovaný binárním kódem převeden na paměťové médium. Tento nástroj byl značně primitivní, protože pouze dokázal převést několik jednoduchých instrukcí do binárního kódu. Na platformě IBM 650 se tento nástroj jmenoval A1 (A od slova assembler). Následně byl v tomto primitivním assembleru naprogramován složitější assembler nazvaný A2, který již rozuměl celé instrukční sadě. V ještě dalším kroku vznikl SAOP (Symbolic Optimal Assembly Program), v němž se nakonec naprogramovaly další základní nástroje – překladač, linker, loader programů, pomocné nástroje aj.

Obrázek 11: Klasické assemblery na osmibitových mikropočítačích již vznikaly v jiném assembleru. Ovšem operační systém (nahraný do ROM) typicky vznikal na minipočítačích, tj. nejednalo se o klasický bootstraping.
9. Projekt Stage0
Konečně se dostáváme k projektům, jejichž cílem je realizace bootstrapingu překladače takovým způsobem, aby každý další krok mohl být plně verifikovatelný znalým uživatelem. První z těchto projektů se jmenuje Stage0. Informace o tomto projektu nalezneme na adrese https://bootstrapping.miraheze.org/wiki/Stage0, všechny zdrojové kódy i obrazy disket pak na GitHubu, konkrétně na adrese https://github.com/oriansj/stage0. V současné podobě není poslední fází bootstrapingu překladač céčka (ostatně se jedná o one man show, takže nemůžeme čekat zázraky), ovšem namísto toho dostane uživatel k dispozici interaktivní prostředí s programovacím jazykem FORTH a taktéž interpret LISPu (resp. jednoho z desítek či spíše stovek dialektů tohoto jazyka).
V rámci tohoto projektu vznikla i specifikace virtuálního stroje, nad kterým jsou všechny nástroje implementovány. Ve skutečnosti se vlastně jedná o definici instrukční sady (která se nijak nevymyká obvyklým instrukčním sadám registrových CPU, ale autor se zde nemusel omezovat šířkou instrukcí ani snahou o čistý RISC), do které je doplněno pět pseudoinstrukcí pro práci se zařízeními: FOPEN_READ, FOPEN_WRITE, FCLOSE, REWIND a SEEK. VM má k dispozici tři zařízení, a to konzoli a dále pásku 1 a pásku 2 (což jsou idealizovaná zařízení s nenáhodným přístupem).
10. Základní sada nástrojů vyvinutých v rámci projektu Stage0
Již víme, že každý projekt pro bootstrap překladače musí obsahovat sadu nástrojů, přičemž ty nejjednodušší nástroje slouží pro postupné vytváření nástrojů složitějších a složitějších (ovšem i náležitě abstraktnějších). Nejinak je tomu i v projektu Stage0. První nástroj se jmenuje hex0 a jedná se skutečně o dosti syrovou, ovšem snadno verifikovatelnou aplikaci. Úkolem tohoto nástroje je načítat dvojice hexadecimálních číslic a převádět je na bajty. Podporovány jsou i řádkové komentáře začínající na # a ;. Všechny ostatní znaky by měly být ignorovány. Například následující zdrojový kód představuje program, který po svém spuštění pouze nastaví návratový kód a ukončí se. hex0 zpracovává pouze hexadecimální číslice, takže zápis instrukcí je zde pouze pro programátora:
48 c7 c0 3c 00 00 00 # mov $0x3c,%rax 48 c7 c7 00 00 00 00 # mov $0x0,%rdi 0f 05 # syscall
V GNU Assembleru by tento program mohl vypadat takto:
# Linux kernel system call table
sys_exit=60
#-----------------------------------------------------------------------------
.section .data
#-----------------------------------------------------------------------------
.section .bss
#-----------------------------------------------------------------------------
.section .text
.global _start # tento symbol ma byt dostupny i linkeru
_start:
movl $sys_exit,%eax # cislo sycallu pro funkci "exit"
movl $0,%edi # exit code = 0
syscall # volani Linuxoveho kernelu
Následují nástroje nazvané hex1 a hex2, přičemž první z nich je pochopitelně implementován v hex0 a druhý v hex1. Tyto nástroje přidávají jednu zásadní novinku – možnost zápisu symbolických adres (formou návěští – label), protože ruční překlad instrukcí je sice (s tabulkou) jednoduchý, ovšem výpočet relativních skoků, adres proměnných atd. je již o mnoho pracnější. Příklad programu zapsaného v hex2:
18020000 # LOADe2 R0 R2 0 23010000 # STORE32 R0 R1 0 :Identify_Macros_1 18010000 # LOAD32 R0 R1 0 A0300000 # CMPSKIPI.NE R0 0 3C00 @Identify_Macros_Done # JUMP @Identify_Macros_Done ; Be done # ;; Otherwise keep looping 3C00 @Identify_Macros_0 # JUMP @Identify_Macros_0 :Identify_Macros_Done # ;; Restore registers 0902803F # POPR R3 R15 0902802F # POPR R2 R15 0902801F # POPR R1 R15 0902800F # POPR R0 R15 0D01001F # RET R15 :Identify_Macros_string 444546494E450000 # "DEFINE"
Povšimněte si, že návěští začínají dvojtečkou (nástroj si musí adresu zapamatovat) a relativní adresa se zapisuje přes zavináč. Podporovány jsou i absolutní adresy zapisované přes znaky dolar a &.
11. Další nástroje, které nalezneme v projektu Stage0
Nástroj hex2 poskytuje dostatečnou úroveň abstrakce pro implementaci assembleru nazvaného m0, jehož zdrojový kód můžete nalézt na adrese http://git.savannah.nongnu.org/cgit/stage0.git/tree/stage1/M0-macro.hex2. S assemblerem se již dostáváme do známé oblasti a mohli bychom říci, že klasický bootstraping by zde mohl skončit.
Autor však ještě doplnil další více či méně hodnotné nástroje. Především se jedná o implementaci programovacího jazyka FORTH a taktéž o již výše zmíněný interpret jazyka LISP. V současnosti se čeká na programátora šíleného do takové míry, že by v m0 nebo m1 naprogramoval překladač céčka, čímž by byl celý proces dokončen (v repositáři sice existuje cc_x86.c, ale ve skutečnosti to není plnohodnotný bootstrapovaný céčkový překladač).
Jednotlivé fáze, tak jak jsou v tomto projektu navrženy:
| Fáze | Nástroje |
|---|---|
| 0 | hex0 |
| 1 | hex1, hex2, m0 |
| 2 | m0, implementace Forthu, LISPu a překladače C |
| 3 | Forth, LISP, … |
12. Projekt Bootstrap
Podobnou cestou, i když s vyššími cíli, se vydal i autor toolchainu nazvaného jednoznačně Bootstrap. Tento projekt naleznete na adrese https://github.com/ras52/bootstrap. Autor Richard Smith navrhl rozdělit nástroje do jednotlivých fází bootstrapingu následujícím způsobem:
| Fáze | Nástroje | Popis |
|---|---|---|
| 0 | unhex | odpovídá nástroji hex0 ze Stage0 |
| 1 | unhexl, elfify | odpovídá hex1/2 + výstup do ELF |
| 2 | as | zjednodušený assembler, který nedokáže provádět skoky dopředu (jednoprůchodový) |
| 3 | as, ld | přepis assembleru do assembleru :-) a přidání linkeru |
| 4 | cc, crt0.o, libc.o | jednoduchý překladač jazyka podobného céčku (bez typů) + základní knihovny |
| 5 | ccx, cpp, cc, cmp | překladač céčka, preprocesor atd. |
13. Projekt bcompiler
Projekt nazvaný bcompiler, který naleznete na stránce https://github.com/certik/bcompiler, se v mnoha ohledech podobá oběma předchozím projektům. Taktéž je zde implementován několikafázový bootstraping, od nejjednoduššího nástroje nazvaného hex1 až po vyšší programovací jazyk BCC. Jednotlivé fáze bootstrapingu vypadají v tomto projektu následovně:
| Fáze | Nástroje | Poznámka |
|---|---|---|
| 0 | HEX1 | zhruba odpovídá fázi 0 předchozích nástrojů |
| 1 | HEX2 | zápis instrukcí v hexadecimální soustavě + podpora jednoznakových návěští |
| 2 | HEX3 | vylepšená verze předchozího, čtyřznaková návěští atd. |
| 3 | HEX4 | další vylepšení, libovolná jména návěští, konstanty, skoky atd. |
| 4 | HEX5 | nízkoúrovňový strukturovaný programovací jazyk |
| 5 | BCC | vyšší programovací jazyk připomínající C |
Samozřejmě opět platí, že každý nástroj s vyšší úrovní abstrakce vznikne překladem používajícím předchozí nástroj.
14. Použití druhého překladače pro zjištění modifikovaného kódu
David A. Wheeler ve své disertační práci rozpracoval nápad Henry Spencera na to, jak vyřešit problematiku překladače obsahujícího zadní vrátka. Tato myšlenka je založena na použití dalšího překladače, kterému věříme a který nemusí být nijak kvalitní z hlediska výkonu – může být pomalý, může produkovat pomalý nebo neefektivní kód atd. To nám nebude příliš vadit, protože tento překladač použijeme pouze jedenkrát. Podívejme se na následující diagram:
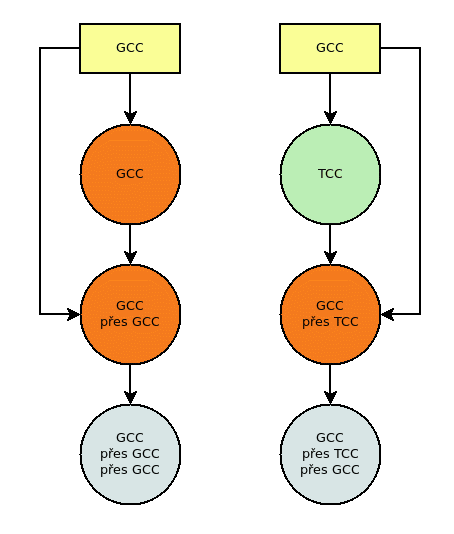
Obrázek 12: Obrana proti zadním vrátkům vloženým do binárního kódu překladače.
Tento diagram ukazuje situaci, kdy nevěříme překladači GCC (jedná se jen o příklad!). Předpokládáme tedy, že v binární podobě překladače mohou být zadní vrátka. Současně ovšem máme k dispozici verifikovaný překladač (zde pro příklad tcc) a budeme chtít získat novou binární podobu GCC bez zadních vrátek. Celý proces je naznačen na diagramu:
- Na začátku máme zdrojové kódy GCC, samozřejmě bez zadních vrátek (útočník není tak naivní, aby nám dal jejich kód k dispozici).
- Přeložíme zdrojové kódy GCC pomocí (pravděpodobně napadeného) GCC. Získáme novou podobu binárního GCC, které buď obsahuje nebo neobsahuje zadní vrátka (což zatím nevíme).
- Provedeme ještě jeden překlad téhož, takže budeme mít GCC přeložené GCC z přeloženého GCC. Výsledek nazvěme gcc_A
- Přeložíme zdrojové kódy GCC pomocí tcc. Tomu věříme a vzhledem k bodu číslo 1 získáme sice pomalý, ovšem bezpečný překladač GCC.
- Tento nový překladač (je bez zadních vrátek!) použijeme pro opětovný překlad GCC. Výsledek nazvěme gcc_B
- Porovnáme binární obrazy gcc_A a gcc_B. Pokud jsou shodné, máme vyhráno a víme, že původní GCC nebyl napaden (popř. že je napaden jak GCC tak naprosto stejně i tcc, ale to je již dosti paranoidní). Pokud jsou výsledné soubory různé, máme problém a je nutné zjistit, proč tomu tak je (v úvahu přichází nedeterminismus překladače, časová razítka, telemetrické informace atd.)
Kromě překladače céčka patřícího do skupiny nástrojů GCC (i samotný překladač se jmenuje GCC – GNU C Compiler, což může být poněkud matoucí – je nutné vždy sledovat kontext, ve kterém se o GCC mluví či píše) je možné v operačním systému Linux použít i další překladače programovacího jazyka C. Mezi ně patří například Clang z projektu LLVM, jenž je zajímavý především po technologické stránce i z hlediska výpočetního výkonu výsledných binárních souborů. Dále se pak můžeme setkat s překladači komerčních firem, například překladačem vytvořeným společností Intel, který v případě některých typů optimalizací překonává GCC. V neposlední řadě je pak možné v Linuxu (a nutno říci, že nejenom v něm) použít překladač nazvaný Tiny C Compiler (tcc), jehož krátkým popisem a porovnáním s GCC se budeme zabývat v následující kapitole.
15. Překladač tcc
Tiny C Compiler (tcc) je název překladače programovacího jazyka C, který byl původně vytvořen Fabrice Bellardem a nyní se o jeho další vývoj a portaci na nové platformy stará komunita vývojářů, protože se samozřejmě jedná o open source projekt. Tiny C Compiler kromě vlastního překladače v sobě obsahuje i linker, což znamená, že jeden binární program může sloužit jak pro překlad zdrojových textů (včetně preprocesingu) do objektového kódu, tak i pro vytvoření výsledného spustitelného binárního programu. Všechny tři zmíněné funkce jsou implementovány v jediném spustitelném souboru, jehož velikost na platformě x86 nepřesahuje sto kilobajtů, což je například v porovnání s GCC zcela zanedbatelná velikost (dokonce i pouze GNU assembler je v binární podobě větší, než celý tcc).
Tiny C Compiler podporuje standard C89/C90 i velkou část standardu C99, a to do té míry, že úpravy zdrojových kódů určených pro GCC většinou nejsou zapotřebí. Největší devizou překladače tcc je blesková rychlost překladu, protože vlastní překlad je jednoprůchodový. Na stránkách tohoto projektu se uvádí, že tcc je přibližně osmkrát rychlejší než překladač GCC (s použitím standardních voleb, tj. bez optimalizací), ovšem jak se můžete dozvědět z tohoto článku, může být tcc v extrémním případě rychlejší zhruba čtyřicetkrát (!). Na druhou stranu však tcc za většinou ostatních moderních překladačů céčka pokulhává v případě optimalizací prováděných při překladu.
Pro nás je ovšem v kontextu dnešního článku nejzajímavější fakt, že Tiny C Compiler lze úspěšně použít pro překlad GCC a naopak. Tím by se – alespoň teoreticky – mohl vyřešit problém, se kterým jsme se seznámili v předchozí kapitole.
16. Postačuje provést překlad gcc s využitím tcc?
Mohlo by se zdát, že pokud použijeme pro překlad GNU C překladače (nebo libovolného jiného překladače, kterému v daný okamžik nedůvěřujeme) přímo alternativní překladač tcc, byl problém důvěry vyřešen, protože nový binární soubor gcc sice bude relativně pomalý (Tiny C Compiler nedokáže provádět složitější optimalizace), ale jeho chování by mělo odpovídat jeho zdrojovým kódům. Ve skutečnosti tomu tak bohužel není, protože samotný tcc sice provede překlad, ovšem samotný překlad je jen součástí celého procesu vytvoření nového binárního souboru. Kromě toho se totiž používají další nástroje spouštěné například ze skriptu configure. A tyto nástroje bývají přeloženy právě (možná napadeným) překladačem gcc. Na druhou stranu ovšem tcc používá vlastní linker, takže jsme na tom paradoxně lépe, než při snaze o použití assembleru.
Co to znamená v praxi? Stále je nutné provést postup dvojí kompilace zmíněný ve čtrnácté kapitole.
17. Alternativní cesta: jednoduché a verifikovatelné virtuální stroje
Existuje samozřejmě i další cesta, jak se vyhnout záludnostem zadních vrátek, ovšem tato cesta je použitelná pouze v některých dosti specifických situacích (například při vývoji jednoúčelových zařízení atd.). Princip je jednoduchý – namísto běžných programovacích jazyků, jejichž překladače nebo interpretry jsou dosti komplikované, se použije takový jazyk, pro nějž postačuje napsat jen malé a většinou i snadno verifikovatelné nástroje. Kromě esoterických jazyků odvozených například od známého Brainfucku jsou k dispozici reálně použitelné jazyky spadající do této kategorie. Vzhledem k tomu, že se v kontextu tohoto článku jedná spíše o okrajové téma, zmíníme se o dvou jazycích, které vznikly – což asi nebude náhoda – již v sedmdesátých letech minulého století, vlastně totožně s vývojem první generace mikroprocesorů (i když je nutné přiznat, že FORTH vývoj reálně použitelných mikroprocesorů o několik let předběhl).
Zajímavé také je, že oba dále zmíněné jazyky používají pro běh v nich napsaných programů popř. pro běh interpretru vlastní virtuální stroj. Pod pojmem „virtuální stroj“ si však nesmíme představovat některé moderní implementace typu JVM. Ve skutečnosti mají implementace těchto VM většinou velikost do několika stovek bajtů, maximálně jednotek kilobajtů.
18. Forth
Programovacímu jazyku Forth jsme se již na stránkách Rootu kdysi věnovali v samostatném seriálu. Tento jazyk, který je založený na konceptu dvou zásobníků (jeden je používaný pro operandy a druhý pro uložení návratových adres volajících funkcí), je známý mj. i tím, že jeho implementaci lze v nejjednodušší variantě provést v několika stovkách bajtů paměti, tj. přibližně s 300 až 500 strojovými instrukcemi a navíc se některé dialekty Forthu provozovaly bez použití operačního systému (Forthovské jazyky byly součástí i několika BIOSů). V takto malém počtu instrukcí bude složité uložit jakákoli nebezpečná zadní vrátka. Na druhou stranu je nutné poznamenat, že Forth tvoří svůj velmi zajímavý, ale dosti izolovaný svět, takže v něm pravděpodobně nikdy nevznikne překladač C ani dalšího vyššího programovacího jazyka (typicky se ovšem Forth spojuje s assemblerem, což je ostatně i logičtější).
19. Tiny BASIC
Zajímavě je koncipován i jazyk Tiny BASIC, jehož specifikace byla napsána Dennisem Allisonem. Tento jazyk vznikl částečně jako reakce na známý otevřený dopis Billa Gatese komunitě „pirátů“. Na základě článku Dennise Allisona vzniklo a vzápětí se i rozšířilo několik různých implementací BASICu, které byly většinou nazvány (opět podle článku) Tiny BASIC. Tyto implementace byly dostupné jak pro osmibitové mikroprocesory firmy Intel, tak i pro procesor Motorola 6800 či MOS 6502, a to buď zcela zdarma nebo pod de-facto symbolickou částkou pěti dolarů (tato částka většinou zahrnovala i poštovné). Ovšem díky vzniku tolik žádoucí konkurence na trhu s domácími osmibitovými počítači se firmy začaly přetahovat o zákazníky, takže se snažily nabízet počítače již se základním programovým vybavením (uloženým v naprosté většině případů přímo v ROM) a nejenom skládačku typu počítače Altair, kde si uživatelé kromě ceny za počítač (400 dolarů) většinou museli připlatit i již zmíněných 150 dolarů za interpret programovacího jazyka.

Tiny Basic je sám o sobě dosti primitivní a v prakticky všech ohledech překonaný jazyk, ovšem zmiňujeme se o něm z toho důvodu, že existoval ve dvou variantách. První variantou byl klasický interpret implementovaný v assembleru nějakého mikroprocesoru (například Intel 8080, MOS 6502 nebo Motorola 6800). Zajímavější je druhá varianta, která sice taktéž byla realizována formou interpretru, ovšem tento interpret běžel nad výše zmíněným virtuálním strojem.
To ovšem samotnou interpretaci programů dále zpomalilo, protože si musíme uvědomit, že interpret BASICu je pomalý sám o sobě a navíc byla rychlost všech tehdy používaných osmibitových mikroprocesorů v porovnání s dneškem až neuvěřitelně nízká :) Proč tedy tvůrci přistoupili na tuto variantu? Důvodem je fakt, že implementace interpretru nad vhodně navrženou VM byla velmi jednoduchá – celý interpret zabral pouze cca 120 instrukcí virtuálního stroje! Samotná implementace VM ve strojovém kódu se společně s interpretrem mohla vejít do 2kB až 3kB operační paměti, což je sice více, než v případě výše popsaných nástrojů typu hex0, ovšem stále se jedná o rozsah, který by měl být verifikovatelný znalým uživatelem. Zdrojový kód interpretru i VM naleznete na adrese http://www.ittybittycomputers.com/IttyBitty/TinyBasic/TB_6800.asm (samotný VM, zde nazývaný IL/Intermediate Language, je na konci výpisu).
20. Odkazy na Internetu
- Defending Against Compiler-Based Backdoors
https://blog.regehr.org/archives/1241 - Reflections on Trusting Trust
https://www.win.tue.nl/~aeb/linux/hh/thompson/trust.html - Coding Machines (povídka)
https://www.teamten.com/lawrence/writings/coding-machines/ - Stage0
https://bootstrapping.miraheze.org/wiki/Stage0 - Projekt stage0 na GitHubu
https://github.com/oriansj/stage0 - Bootstraping wiki
https://bootstrapping.miraheze.org/wiki/Main_Page - Bootstrapped 6502 Assembler
https://github.com/robinluckey/bootstrap-6502 - IBM Basic assembly language and successors (Wikipedia)
https://en.wikipedia.org/wiki/IBM_Basic_assembly_language_and_successors - X86 Assembly/Bootloaders
https://en.wikibooks.org/wiki/X86_Assembly/Bootloaders - run6502, lib6502 — 6502 microprocessor emulator
http://piumarta.com/software/lib6502/ - Simple Computer Simulator Instruction-Set
http://www.science.smith.edu/dftwiki/index.php/Simple_Computer_Simulator_Instruction-Set - Bootstrapping#Computing (Wikipedia)
https://en.wikipedia.org/wiki/Bootstrapping#Computing - Bootstrapping (compilers)
https://en.wikipedia.org/wiki/Bootstrapping_%28compilers%29 - Bootstrapable Builds
http://bootstrappable.org/ - What is a coder's worst nightmare?
https://www.quora.com/What-is-a-coders-worst-nightmare/answer/Mick-Stute - Linux Assembly
http://asm.sourceforge.net/ - Tombstone diagram (Wikipedia)
https://en.wikipedia.org/wiki/Tombstone_diagram - History of compiler construction (Wikipedia)
https://en.wikipedia.org/wiki/History_of_compiler_construction - Self-hosting (Wikipedia)
https://en.wikipedia.org/wiki/Self-hosting - GNU Mes: Maxwell Equations of Software
https://gitlab.com/janneke/mes - Tiny C Compiler
https://bellard.org/tcc/ - Welcome to C–
https://www.cs.tufts.edu/~nr/c--/index.html - c4 – C in four functions
https://github.com/rswier/c4 - Tiny BASIC (Wikipedia)
https://en.wikipedia.org/wiki/Tiny_BASIC - David A. Wheeler’s Page on Fully Countering Trusting Trust through Diverse Double-Compiling (DDC) – Countering Trojan Horse attacks on Compilers
https://www.dwheeler.com/trusting-trust/ - Reviewing Microsoft's Automatic Insertion of Telemetry into C++ Binaries
https://www.infoq.com/news/2016/06/visual-cpp-telemetry - Visual Studio adding telemetry function calls to binary?
https://www.reddit.com/r/cpp/comments/4ibauu/visual_studio_adding_telemetry_function_calls_to/d30dmvu/ - LWN – The Trojan Horse
https://www.dwheeler.com/trusting-trust/spencer-19981123.txt - reproducible-builds.org
https://reproducible-builds.org/ - Other Assemblers
http://asm.sourceforge.net/howto/other.html - Projekt bootstrap
https://github.com/ras52/bootstrap - Projekt bcompiler
https://github.com/certik/bcompiler - Zadní vrátka
https://cs.wikipedia.org/wiki/Zadn%C3%AD_vr%C3%A1tka#Reflections_on_Trusting_Trust - David A. Wheeler’s Personal Home Page
https://www.dwheeler.com/ - David A. Wheeler
https://en.wikipedia.org/wiki/David_A._Wheeler - Multics Security Evaluation: Vulnerability Analysis
http://csrc.nist.gov/publications/history/karg74.pdf - Reflections on Rusting Trust
https://manishearth.github.io/blog/2016/12/02/reflections-on-rusting-trust/ - Reflections on Trusting Trust for Go (slajdy)
https://www.slideshare.net/yeokm1/reflections-on-trusting-trust-for-go - Reflections on Trusting Trust for Go (zdrojové materiály)
https://github.com/yeokm1/reflections-on-trusting-trust-go - Reflections on Trusting Trust for Go – GopherConSG 2018
https://www.youtube.com/watch?v=T82JttlJf60 - Reproducing Go binaries byte-by-byte
https://blog.filippo.io/reproducing-go-binaries-byte-by-byte/ - Trojský kůň
https://cs.wikipedia.org/wiki/Trojsk%C3%BD_k%C5%AF%C5%88_%28program%29


























 ČLÁNKY DO MAILU
ČLÁNKY DO MAILU